De acordo com SILBERSCHATZ (2006), o processamento de dados tem impulsionado o crescimento dos computadores desde os primeiros dias dos computadores comerciais, na verdade, a automação das tarefas de processamento de dados já existia antes mesmo dos computadores. Cartões perfurados foram usados no início do século XX para registrar dados de senso e sistemas mecânicos foram usados para processar os cartões e tabular os resultados.
Com a evolução dos meios de armazenamento iniciados na década de 50 com as fitas magnéticas chegando aos discos rígidos na década de 60, e com o aperfeiçoamento das metodologias de criação de banco de dados saindo do modelo hierárquico, década de 80, para o relacional, década de 90, chegamos a explosão da Word Wide Web, onde os bancos são utilizados muito mais extensivamente, como jamais foram, com taxas de processamento muito altas, onde deve-se ter grande confiabilidade e disponibilidade (24h por dia, 7 dias por semana).
Conforme TAKAI (2005), atualmente, devem-se considerar alguns aspectos relevantes para atingir a eficiência e a eficácia dos sistemas informatizados desenvolvidos, a fim de atender seus usuários nos mais variados domínios de aplicação. Tais aspectos são:
• Os projetos Lógicos e Funcionais do Banco de Dados devem ser capazes de prever o volume de informações armazenadas a curto, médio e longo prazo. Os projetos devem ter uma grande capacidade de adaptação;
• Deve-se ter generalidade e alto grau de abstração de dados, possibilitando confiabilidade e eficiência no armazenamento dos dados e permitindo a utilização de diferentes tipos de gerenciadores de dados através de linguagens de consultas padronizadas;
• Projeto de uma interface ágil e para propiciar aprendizado suave ao usuário, no intuito de minimizar o esforço cognitivo;
• Implementação de um projeto de interface compatível com múltiplas plataformas (UNIX, Windows, Linux etc.);
• Independência de Implementação da Interface em relação aos SGBDs que darão condições às operações de armazenamento de informações (Oracle, SysBase, FireBird, SQL Server etc.);
• Independência da metodologia a ser utilizada no desenvolvimento do sistema (orientação a objeto, orientação a eventos) ou linguagem (Delphi, Visual Basic, Rubi, C++ etc.).
A definição geral para banco de dados conforme KROENKE (1999) é que um banco de dados é um modelo da realidade ou de alguma porção dela, já que se relaciona a um negócio. Entretanto, isto não é verdade. Um banco de dados não modela a realidade de nenhum modo, em vez disso, é um modelo do modelo do usuário.
Uma outra definição que temos, de acordo com Machado (2004) é que banco de dados:
“[...] pode ser definido como um conjunto de dados devidamente relacionados. Podemos compreender como dados os objetos conhecidos que podem ser armazenados e que possuem um significado implícito. Porém, o significado do termo banco de dados é mais restrito que simplesmente a definição dada anteriormente. Um banco de dados possui as seguintes propriedades:
• É uma coleção lógica coerente de dados com o significado inerente; uma disposição desordenada dos dados não pode ser referenciada como um banco de dados.
• Ele é projetado, construído e populado com valores de dados para um propósito específico; um banco de dados possui um conjunto predefinido de usuários e aplicações.
• Ele representa algum aspecto do mundo real o qual é chamado de minimundo; qualquer alteração efetuada no minimundo é automaticamente refletida no banco de dados [...]” (MACHADO, 2004, p.20)
O projeto de um ambiente de aplicação de banco de dados completo que atenda às necessidades da empresa sendo modelada requer atenção a um amplo conjunto de aspectos. Esses aspectos adicionais do uso esperado do banco de dados influenciam uma variedade de escolhas de projeto nos níveis físico, lógico e visual.
De acordo com SILBERSCHATZ (2006), os sistemas de banco de dados são projetados para gerenciar grandes blocos de informações que não existem isolados, pois eles são partes da operação cujo produto final pode ser informações do banco de dados ou pode ser algum dispositivo ou serviço para o qual o banco de dados desempenha um papel de apoio.
A fase inicial do projeto de banco de dados é caracterizar completamente as necessidades de dados dos usuários. O projetista de banco de dados precisa interagir extensivamente com os usuários e estabelecer as seqüências de atividades, através do levantamento de requisitos, da empresa em uma ordem que possa resultar em ganhos de produtividade e confiabilidade dos sistemas desenvolvidos.
A utilização de uma abordagem correta de metodologia orientada a modelagem de banco de dados, envolve a estruturação nas três etapas da execução de um projeto: conceitual, lógico e físico.
O projeto conceitual é aquele que deve ser sempre a primeira etapa de um projeto de um banco de dados e que de acordo com SILBERSCHATZ (2006), fornece uma visão geral do ambiente do problema. O projetista revisa o esquema para confirmar se todas as necessidades de dados estão realmente satisfeitas e se não estão em conflito entre si. O foco neste momento é descrever os dados e suas relações, e não especificar detalhes do armazenamento físico.
No projeto lógico, segundo Machado (2004):
“[...] é onde se considera uma das abordagens possíveis da tecnologia de Sistemas Gerenciadores de Banco de Dados (relacional, hierárquica, rede ou orientada a objetos) para a estruturação e estabelecimento da lógica dos relacionamentos existentes entre os dados definidos no modelo conceitual [...] e que [...] descreve em formato as estruturas que estarão no banco de dados de acordo com as possibilidades permitidas pela sua abordagem, mas sem considerar, ainda, nenhuma característica específica de um sistema gerenciador de banco de dados (SGBD) [...]” (MACHADO, 2004, p.21).
No projeto físico, segundo Machado (2004):
“[...] esta é a etapa final do projeto de banco de dados, na qual será utilizada a linguagem de definição de dados do SGBD (DDL) para realização da sua montagem no dicionário de dados. Em ambiente de banco de dados relacional denominados de script de criação de banco de dados, o conjunto de comandos em SQL (DDL), que será executado no Sistema Gerenciador de Banco de Dados para a criação do banco de dados correspondente ao modelo físico [...].” (MACHADO, 2004, p.21).
Uma boa estruturação de um banco de dados deve propiciar o desenvolvimento de um sistema de controle, buscando disponibilizar as informações nele armazenadas com precisão e confiabilidade.
José Luciano Rocha e Marciano Boone
Pesquisa Google

Pesquisa personalizada
quarta-feira, 13 de agosto de 2008
segunda-feira, 21 de abril de 2008
Comandos Linux - Parte III
Vamos a mais alguns comandos:
kudzu - Comando para executar o auto-reconhecimento de um hardware na inicialização do sistema. Ele determina e configura automaticamente o seu hardware.
setserial - Tem como função ajustar a porta serial para uma definição não padrão. Acrescente suas definições no arquivo /etc/rc.d/rc.local, caso você prefira que elas sejam inicializadas com o sistema. Ex.: "setserial /dev/cua0 port 0x03f8 irq 4".
tunelp - Responsável pelo ajuste das portas paralelas.
mount - Comando que permite a utilização do periférico. Sua função é instruir o kernel para que ele inclua o sistema de arquivos encontrado em um dispositivo, disponibilizando-o em um diretório. Ex.: "mount /dev/cdrom /mnt/cdrom", "mount -t auto ext2 /dev/fd0 /mnt/floppy".
unmount - Responsável por desmontar o sistema de arquivos. O diretório de ponto de montagem não dever ser nem o seu diretório corrente, nem o de ninguém mais. Ex.: "unmount /mnt/cdrom", "unmout /mnt/floppy".
fdisk - Utilitário para particionamento físico de discos rígidos. Ex.: "fdisk /dev/hda".
cfdisk - Utilitário de particionamento de disco. Ex.: "cfdisk /dev/hda".
sfdisk - Tem a função de listar a tabela de partições, incluindo partições estendidas, de todos os drivers do sistema. Ex.: "sfdisk -l -x more".
fsck - Sua função é verificar e reparar um sistema de arquivos. Para que este comando seja executado, o linux deve ser iniciado em modo monousuário. Ex.: "fsck -t ext2 /dev/hda2".
free - Exibe a memória usada e a livre. Ex.: "free".
dd - Comando duplicados de dados. Ex.: "dd if=/dev/fd0h1440 of=floppy_image".
mkbootdisk - Sua função é criar um disquete de emergência. Ex.: "mkbootdisk --device /dev/fd0 2.4.2-3".
df - Mostra o espaço ocupado e livre das partições. Ex.: "df".
du - Permite monitorar o uso do disco rígido e exibe o uso detalhado de disco de cada subdiretório, começando pela raiz. Ex.: "du / -bh more", "du -s /etc".
terça-feira, 5 de fevereiro de 2008
Instalação básica do IPCop - Parte II
Continuamos aqui a instalação do IPCop:
9 - Chegamos agora num momento importante da instalação. O IPCop trabalha com um esquema de cores para o gerenciamento das interfaces de rede, conforme a figura abaixo:
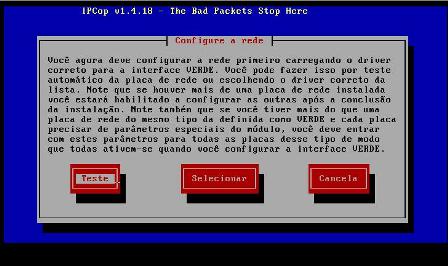
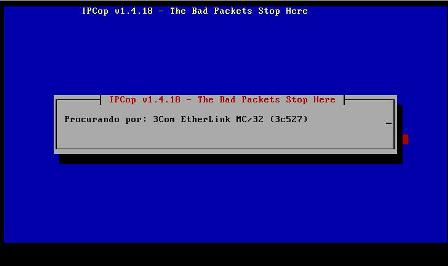
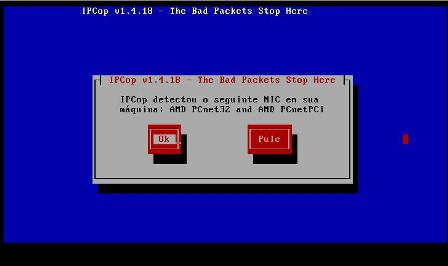
10 - A interface green corresponde à nossa placa de rede local e podemos seleciona-la neste momento, escolhendo a opção "Teste" para que o IPCop procure a placa e escolha o melhor módulo para a mesma, no entanto, se soubermos qual é o modelo exato da placa, podemos escolher a opção "Selecionar" e em seguida, manualmente, escolheremos em uma lista, o modelo referente a nossa placa:
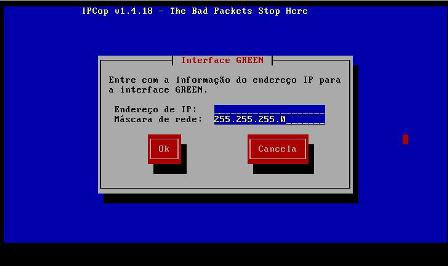
11 - Será solicitado pelo IPCop o endereço ip da interface green:
12 - A próxima tela informa que a instalação foi realizada com sucesso:
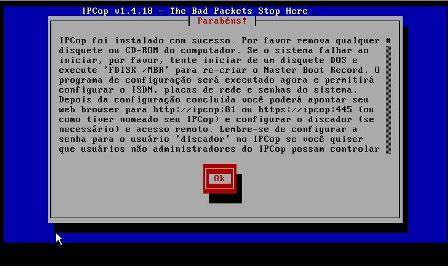
A seguir, iremos configurar o IPCop de acordo com as nossas necessidades, definindo tipo de teclado, rede, dhcp, dns, etc.
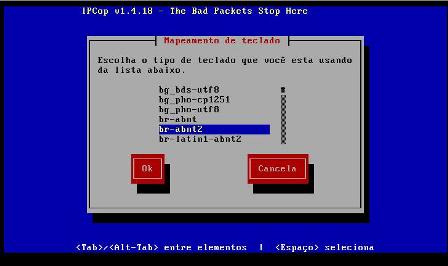
13 - Escolheremos a seguir o layout do teclado que iremos utilizar.
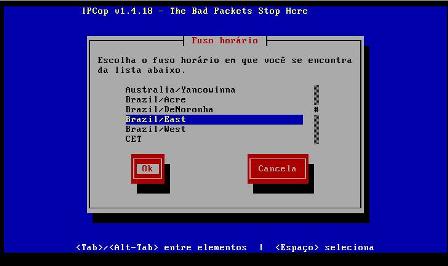
14 - Agora devemos escolher a zona do fuso horário do sistema:
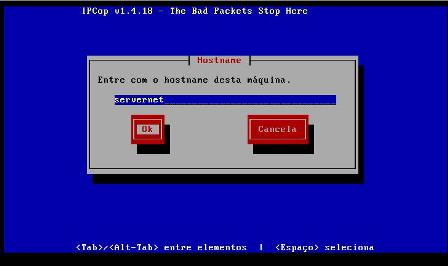
15 - Definiremos agora o nome da máquina:
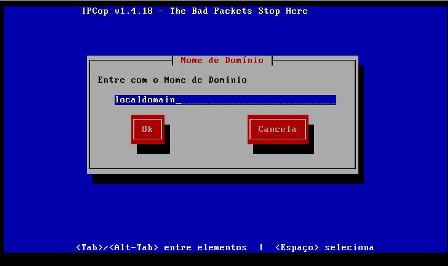
16 - A seguir definiremos o domínio o qual a máquina pertence:
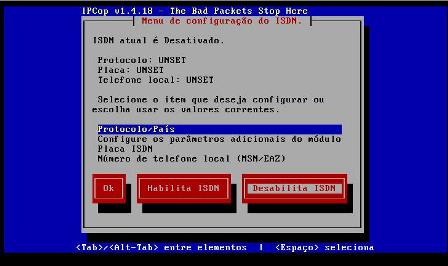
17 - Na próxima tela temos a configuração do ISDN. Em nossa instalação não utilizaremos esta opção de conexão (que ainda usa o sistema telefônico comum e com isso gera custos com pulso), desativando a mesma:
Continua no próximo post. Quem quiser ver o vídeo da instalação completa é só acessar: http://br.youtube.com/watch?v=jeFoq7tuKxw
quarta-feira, 23 de janeiro de 2008
Comandos Linux - Parte II
Veremos agora comandos importantes para o acompanhamento e a identificação das ocorrências básicas do sistema e sua utilização por parte dos usuários.
Para obtermos informações sobre o sistema temos:
uname - Mostra a versão do kernel da distribuição linux usada. Ex.: "uname -a", "uname -r", "uname -m".
lspci - Mostra as informações (nome da interface, número e posição no barramento, modelo, versão, etc) sobre as placas PCI instaladas no computador. Ex.: "lspci -v", "lspci -vv".
pwd - Este comando é usado para mostrar o diretório corrente. Ex.: "pwd".
hostname - Com este comando, você pode conferir o nome da máquina e o host local. Ex.: "hostname".
whoami - Por meio deste comando, você pode ver o nome do usuário logado. Ex.: "whoami".
w - Este comando lista os usuários que estão logados no sistema linux. A lista mostra o login, a hora em que o usuário logou-se, o aplicativo em que encontra-se e a quanto tempo, entre outras informações. Ex.: "w".
who - Comando usado para determinar a quantidade e identidade dos usuários que estão utilizando o sistema no momento. Ex.: "who -a", "who -H", "who -s", "who -q", "who -l".
rwho - Mostra usuários logados em outros computadores da rede. O serviço rwho deve estar habilitado par este comando rodar. Ex.: "rwho -a".
id - Tem como função exibir a identificação do usuário (user id ou uid) e o grupo de identifiacação (group id ou gid). Ex.: "id nomedousuário.
date - Mostra e ajusta a data e hora do sistema. Opções:
%a - abrevia o dia da semana;
%A - nome da semana por extenso;
%b - abrevia o mês;
%B - nome do mês por extenso;
%c - apresenta o nome do dia e do mês abreviados;
%d - apresenta o mês em formato numérico;
%D - mostra a data no formato mmddyy;
%y - mostra apenas os dois últimos dígitos do ano;
%Y - mostra os quatro dígitos do ano
Ex.: Mudar a data e hora para 23/01/2008 12:00h - "date MMDDhhmmAAAA - date 012812002008"
MM - mês / DD - dia / hh - hora / mm - minutos / AAAA - ano
time - Determina a quantidade de tempo gasto durante a execução de um determinado comando. Ex.: "time ls", "time lspci".
uptime - Mostra a quantidade de tempo decorrido desde o último reboot. Ex.: "uptime".
last - Mostra um log dos usuários e terminais utilizados. Ex.: "last".
lastb - Aqui você pode conferir a última tentativa de login malsucedida no sistema, que fica armazenada em var/log/btmp. Ex.: "lastb".
history - Mostra os últimos 1000 comandos executados em modo texto na sessão atual. Ex.: "history".
ps - Responsável por mostrar a situação dos processos atuais no sistema, executados pelo usuário. Ex.: "ps -aux", "ps -ef".
lsmod - Mostra os módulos do kernel que estão sendo carregados na memória naquele exato momento. Ex.: "lsmod".
set - Tem como função exibir o ambiente completo do usuário atual. Ex.: "set".
echo - Permite que você verifique o conteúdo de uma variável de ambiente. Ex.: "echo $PATH".
dmesg - Mostra as mensagens do kernel, ou seja, o conteúdo do chamado buffering do kernel. Ex.: "dmesg less".
chage - Possibilita visualizar as informações sobre a expiração do password. "chage -l nomedousuário".
quota - Mostra os limites do usuário sobre o uso do espaço em disco. Ex.: "quota".
runlevel - Nível de execução do sistema. Indica o modo de operação atual da máquina, definindo quais serviços e recursos devem permanecer ativos. Pode ser trocado a qualquer momento pelo comando init. O runlevel padrão está definido no arquivo /etc/inittab. Os seguintes runlevels são padronizados:
0 - halt;
1 - modo monousuário;
2 - modo multiusuário, sem NFS;
3 - modo multiusuário completo;
4 - não usado;
5 - modo gráfico - X11;
6 - reinicialização do sistema.
Continua no próximo post.
sábado, 19 de janeiro de 2008
Comandos Linux - Parte I
Veremos a seguir alguns comandos que podem vir a ser úteis no seu dia a dia como administrador de um sistema linux.
Para as operações básicas temos:
login - Abre uma nova sessão para um usuário. Esta nova sessão assume o perfil do usuário, com todas as características associadas a ele.
Ex.: "login [nome do usuário]".
logout - Tem como função desconectar um usuário de uma determinada sessão.
exit - Seu objetivo é encerrar uma sessão ativa, ou seja, deixar um usuário para acessar com outro ou voltar para outra sessão.
shutdown - Encerra todas as atividades do linux e prepara o micro para ser desligado.
Ex.: "shutdown now" (desliga o micro),
"shutdown -r now" (reinicializa o micro).
halt , reboot , init 6 - Comandos responsáveis pela reinicialização da máquina.
cd - Semelhante ao "cd" do DOS, tem como tarefa mudar o diretório corrente.
Ex.: "cd /usr/bin",
"cd .." (volta um nível),
"cd /" (vai para o diretório raiz)
ls - Semelhante ao "Dir" do DOS (listar arquivos e diretórios). Pode pertencer ao diretório atual ou a um diretório referenciado após a barra(/).
Ex.: "ls /usr/local",
"ls -la /usr/local (mostra também os arquivos ocultos e outras informações sobre os arquivos e diretórios e as definições de cada arquivo),
"ls /usr/local less" (lista os arquivos e diretórios e para por página).
./nome_do_programa - Utilizado para rodar um executável no diretório atual. Os caracteres"./" são necessários quando o executável não está no PATH.
Ex.: "./kcalc".
clear - limpa a tela.
Continua no próximo post.
terça-feira, 8 de janeiro de 2008
Instalação básica do IPCop - Parte I
O IPCop Firewall é uma distribuição linux voltada a proteção de
um simples computador ou de rede de pequeno a médio porte.
Possui diversas ferramentas que podem ser integradas ao seu
sistema como VPN, QOS, PROXY, FIREWALL, IDS entre
outras.
A página oficial do IPCop é: www.ipcop.org e sua versão mais
outras.
A página oficial do IPCop é: www.ipcop.org e sua versão mais
atual é a 1.4.18.
O link para download é:
http://ufpr.dl.sourceforge.net/sourceforge/ipcop/ipcop-1.4.18-install-cd.i386.iso
Veremos a seguir a instalação básica dele:
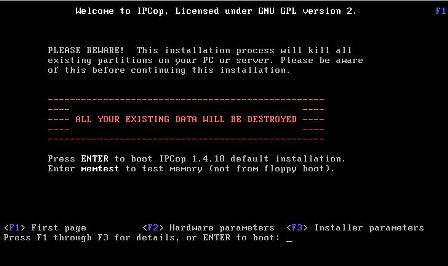
1 - Tela inicial. Pressione Enter para continuar ou para uma instalação
personalizada, pressione F2 ou F3:
O link para download é:
http://ufpr.dl.sourceforge.net/sourceforge/ipcop/ipcop-1.4.18-install-cd.i386.iso
Veremos a seguir a instalação básica dele:
1 - Tela inicial. Pressione Enter para continuar ou para uma instalação
personalizada, pressione F2 ou F3:
2 - Pressionando F2 é mostrada um tela com as opções de Hardware:

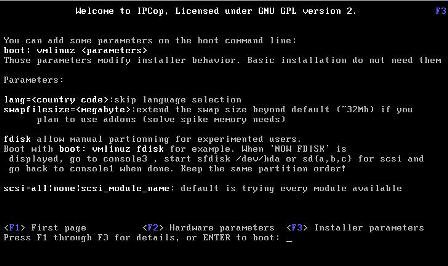
3 - Pressionando F3 temos uma tela com parametros de boot:
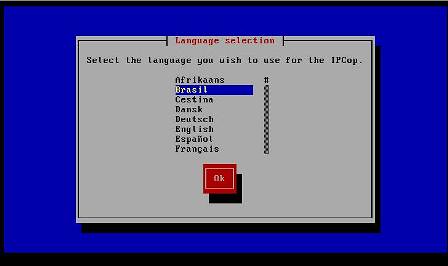
4 - Seleção do Idioma. Utilizaremos "Brasil" para facilitar o entendimento da instalação:
5 - Tela de apresentação. Pressione Enter:

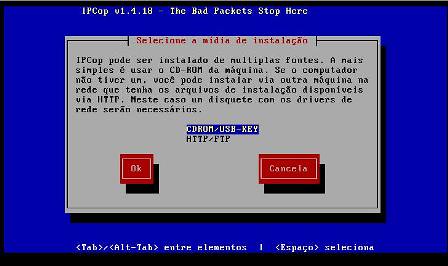
6 - Escolha a opção de origem para instalação do IPCop (geralmente CD-ROM):
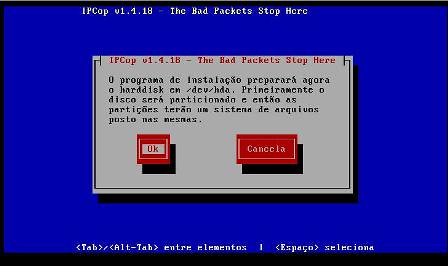
7 - Neste momento, caso você tenha escolhida a opção padrão na tela inicial, a instalação do IPCop irá particionar e formatar seu HD. Tenha certeza disto, pois todas informações nele contidas serão apagadas.
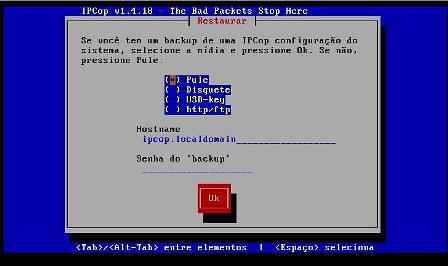
8 - Se você estiver reinstalando o sistema, você tem a opção de carregar um backup realizado. Caso contrário, escolha a opção "Pule" e pressione "OK":
Continua no próximo post.
quinta-feira, 3 de janeiro de 2008
Instalação Básica do IPCop!
Coloquei um vídeo com a instalação básica do Ipcop no youtube. Em breve estarei colocando outros com as instalações de addons e configurações.
Preparei também um tutorial com a instalação, estarei postando em breve.
Preparei também um tutorial com a instalação, estarei postando em breve.
Assinar:
Postagens (Atom)